Google Reader: A Time Capsule from 5 Years Ago #
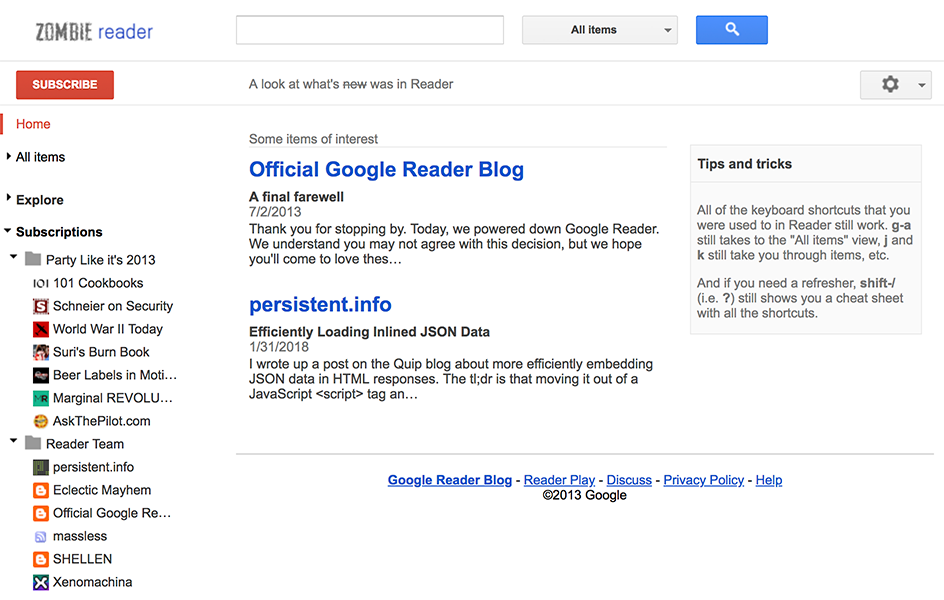 It's now been 5 years since Google Reader was shut down. As a time capsule of that bygone era, I've resurrected readerisdead.com to host a snapshot of what Reader was like in its final moments — visit http://readerisdead.com/reader/ to see a mostly-working Reader user interface.
It's now been 5 years since Google Reader was shut down. As a time capsule of that bygone era, I've resurrected readerisdead.com to host a snapshot of what Reader was like in its final moments — visit http://readerisdead.com/reader/ to see a mostly-working Reader user interface.
Before you get too excited, realize that it is populated with canned data only, and that there is no persistence. On the other hand, the fact that it is an entirely static site means that it is much more likely to keep working indefinitely. I was inspired by the work that Internet Archive has done with getting old software running in a browser — Prince of Persia (which I spent hundreds of hours trying to beat) is only a click away. It seemed unfortunate that something of much more recent vintage was not accessible at all.
Right before the shutdown I had saved a copy of Reader's (public) static assets (compiled JavaScript, CSS, images, etc.) and used it to build a tool for viewing archived data. However, that required a separate server component and was showing private data. It occurred to me that I could instead achieve much of the same effect directly in the browser: the JavaScript was fetching all data via XMLHttpRequest, so it should just be a matter of intercepting all those requests. I initially considered doing this via Service Worker, but I realized that even a simple monkeypatch of the built-in object would work, since I didn't need anything to work offline.
The resulting code is in the static_reader directory of the readerisdead project. It definitely felt strange mixing this modern JavaScript code (written in TypeScript, with a bit of async/await) with Reader's 2011-vintage script. However, it all worked out, without too many surprises. Coming back to the Reader core structures (tags, streams, preferences, etc.) felt very familiar, but there were also some embarrassing moments (why did we serve timestamps as seconds, milliseconds, and microseconds, all within the same structure?).
As for myself, I still use NewsBlur every day, and have even contributed a few patches to it. The main thing that's changed is that I first read Twitter content in it (using pretty much the same setup I described a while back), with a few other sites that I've trained as being important also getting read consistently. Everything else I read much more opportunistically, as opposed to my completionist tendencies of years past. This may just be a reflection of the decreased amount of time that I have for reading content online in general.
NewsBlur has a paid tier, which makes me reasonably confident that it'll be around for years to come. It went from 587 paid users right before the Reader shutdown announcement to 8,424 shortly after to 5,345 now. While not the kind of up-and-to-right curve that would make a VC happy, it should hopefully be a sustainable level for the one person (hi Samuel!) to keep working on it, Pinboard-style.
Looking at the other feed readers that sprung up (or got a big boost in usage) in the wake of Reader's shutdown, they all still seem to be around: Feedly, The Old Reader, FeedWrangler, Feedbin, Innoreader, Reeder, and so on. One of the more notable exceptions is Digg Reader, which itself was shut down earlier this year. But there are also new projects springing up like Evergreen and Elytra and so I'm cautiously optimistic about the feed reading space.
3 Comments
Post a Comment