Screenshot-proof images via temporal dithering #
Snapchat's (and now Facebook Poke's) main claim to fame is that it lets you send "self-destructing" image messages. Setting aside the debate about the uses of this beyond sexting, the key vulnerability in both apps is the built-in ability to take screenshots. Both take a reactive approach, where you're notified if the recipient took a screenshot, but can't really do anything about it.
I was thinking about ways of mitigating this issue, and figured that perhaps turning the image into an animation where individual frames are not (or at least less) recognizable would be the right path. This is a variant of temporal dithering, except we're intentionally pretending like each frame has a limited amount of precision, and only when averaged together is the original image re-created.
I've created a proof of concept (source) of this. It loads the image into a <canvas> and generates a "positive" and "negative" frame out of it. The positive frame has a random offset added to each pixel's RGB components, while the negative one has it subtracted. When displayed in quick sequence (requestAnimationFrame is used to do this every time the screen refreshes) the two offsets should cancel out, and the resulting image should re-appear.
 |
 |
| Source | Temporal dithering1 |
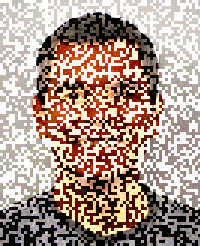 |
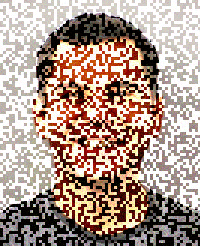 |
| Positive frame | Negative frame |
The resulting flicker is unfortunate, but perhaps that only enhances the furtiveness of an image that will disappear in a few seconds. It also seemed fitting to include Lenna as a source image, given its origin.
Obviously this technique is meant to deter only casual attempts at screen capture. Beyond the analog hole, screen recording software (albeit not an issue on non-jailbroken iOS devices) can easily reconstruct the original image.
Potential areas of exploration are doing the offsets in a different color space (RGB is not linear) and using more than two frames. One option for generating more frames is to keep making random positive and negative pairs. That way repeated screen captures are less likely to yield a pair that can be combined to reconstruct the original image. Another option for generating more frames is to create three or more images that need to be averaged together to yield the original. However, that will result in more image degradation, since the frames are less likely to be perceived as one image; persistence of vision lasts for 1/25th of a second, which is between 2 and 3 frames at 60Hz.
Update: See also the discussion on Hacker News.
- The embedded example in this blog post is rendered as an animated GIF. Due to clamping of GIF frame rates, lack of precision (the delay is specified as an integer counting hundredths of a second) and guessing at the screen's refresh rate (it assumes 60Hz), it will exhibit even more flicker than the programmatic version.


 Bird Feeder lets you sign in with Twitter, and from that generates a "private" Atom feed out of your "with friends" timeline. It tries to be
Bird Feeder lets you sign in with Twitter, and from that generates a "private" Atom feed out of your "with friends" timeline. It tries to be  To that end, I've made
To that end, I've made 

