Accidental DDoSes I Have Known #
A couple of weeks I was migrating some networking code in Quip's Mac app from NSURLConnection to NSURLSession when I noticed that requests were being made significantly more often than I was expecting. While this was great during the migration (since it made exercising that code path easier), it was unexpected: the data should only have been fetched once and then cached.
After some digging, it turned out that we had a bug in the custom local caching system that sits in front our CDN (CloudFront), which we use to serve profile pictures and other non-authenticated data. Due to a catch-22 in the cache key function (which made it depend on the HTTP response), all assets would initially not be found in the local cache, and would incur a network request. The necessary data was then stored in memory, so until the app was restarted the cache would work as expected, but in the next session they would get requested again.
 It turned out that this bug had been introduced a few months prior, but since it manifested itself as a little bit of extra traffic to an external service, we didn't notice it (the only other visible manifestation would be that profile pictures would load more slowly during app startup, or be replaced with placeholders if the user happened to be offline, but we never got any reports of that).
It turned out that this bug had been introduced a few months prior, but since it manifested itself as a little bit of extra traffic to an external service, we didn't notice it (the only other visible manifestation would be that profile pictures would load more slowly during app startup, or be replaced with placeholders if the user happened to be offline, but we never got any reports of that).
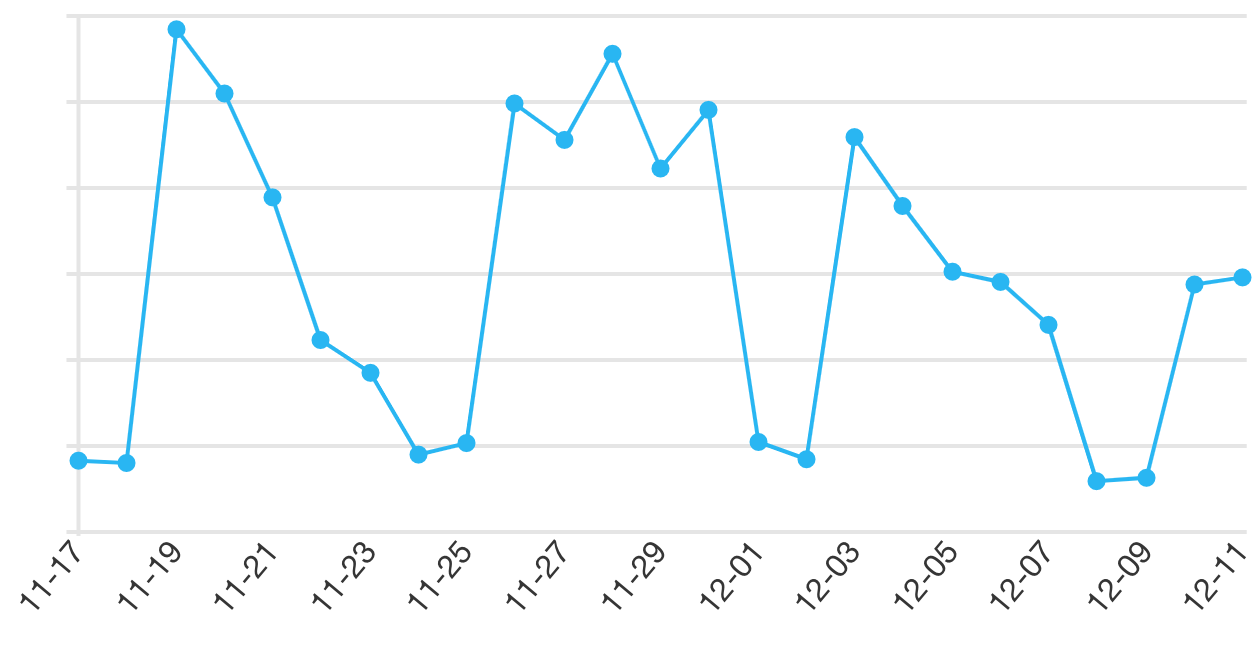
This chart (of CloudFront requests from “Unknown” browsers, which is how our native apps are counted) shows the fix in action; the Mac app build with it was released on November 30th and was picked up by most users over the next few days.
This kind of low-grade accidental DDoS reminded of a similar bug that I investigated a few years ago at Google, while working on Chrome Extensions. A user had reported that the Gmail extension for Chrome (which my team happened to own, since we provided it as sample code) would end up consuming a lot of memory (and eventually be terminated) if the Gmail URL that it tried to fetch data from was blocked by filtering software. After some digging it turned out that the extension would enqueue two retries for every failed failure response, due to code along these lines:
var xhr = new XMLHttpRequest();
... // Send off request
function handleError() {
... // schedule another request
}
xhr.onreadystatechange = function() {
.. // Various early exits if success conditions are met
handleError();
};
xhr.onerror = function() {
handleError();
};
The readystatechange event always fires, including for error states that also invoke the error event handler. This behavior meant that it would quickly escalate from a request every few minutes to almost one request per second, depending on how long it remained in the blocked state. The fix turned out to be trivial, and since this was a separate package distributed via the Chrome Web Store that gets auto-updated, we could quickly fix the millions of users that had it installed.
It then occurred to me that this would not just affect users where the Gmail URL was blocked, but any user that had spotty connectivity — any HTTP failure would result in a doubling of background requests. I then called up a requests-per-second graph of the Atom feed endpoint for Gmail (which is what the extension used), and saw that it had dropped by 20,000 requests per second over the day or so that it took for the extension update to propagate.
The upshot of all this is that Google Reader at its peak had about 10,000 requests per second, thus making my overall traffic contribution to Google net negative.

 It's now been 5 years since Google Reader was
It's now been 5 years since Google Reader was