Google Reader Social Retrospective #
With the upcoming transition of social features in Google Reader to Google+, I thought this would be a good time to look back at the notable social-related events in Reader's history. For those of you who are new here, I was Reader's tech lead from 2006 to 2010.
Late 2004 to early 2005: Chris Wetherell starts work on "Fusion", one of the 20% projects that serve as prototypes for Google Reader. Among other neat features, it has a "People" tab that shows you what other people on the system are subscribed to and reading. There's no concept of a managed friends list, after all when the users are just a few dozen co-workers, we're all friends, right?
September 2005: Ben Darnell and Laurence Gonsalves add the concept of "public tags" to the nascent Reader backend and frontend. There are no complex ACLs, just a single boolean that controls whether a tag is world-readable.
October 2005: A remnant of the "People" tab is present in the HTML of the launched version of Google Reader, and an eagle-eyed Google Blogoscoped forum member notices it and speculates as to its intended use.
March 2006: Tag sharing launches, along with the ability to embed a shared tag as a widget in the sidebar of your blog or other sites. On one hand, tag sharing is quite flexible: you can share both individual items by applying a tag to them, and whole feeds (creating spliced streams) if you share folders. On the other hand, having to create a tag, share it and manually apply it each time is rather tedious. A lot of users end up sharing their starred items instead, since that enables one-click sharing.
Summer of 2006: As part of Brad Hawkes's summer internship, he looks into what can be done to make shared tags more discoverable (right now users have to email each other URLs with 20-digit long URLs). He whips up a prototype that iterates over a user's Gmail contacts and lists shared tags that each contact might have. This is neat, but is shelved for both performance (there's a lot of contacts to scan) and privacy (who exactly is in a user's address book?) concerns.

May 2007: Brad graduates and comes back work on Reader full-time. His starter project is to beef up Reader's support for that old school social network, email.
Fall of 2007: There is growing momentum within Google to have a global (cross-product) friend list, and it looks like the Google Talk buddy list will serve as the seed. Chris and I start to experiment with showing shared items from Talk contacts. We want to use this feature with our personal accounts (i.e. real friends), but at the same time we don't want to leak its existence. I decide to (temporarily) call the combined stream of friends' shared items "amigos". Thankfully, we remember to undo this before launch.

Spring of 2008: With sharing in Reader picking up steam, a few aggregators and leaderboards of shared items start to spring up. Louis Gray comes to the attention of the Reader team (and its users) by discovering the existence of ReadBurner before its creator is ready to announce it.
May 2008: Up until this point sharing has been without commentary; it was up to the reader of the shared item to decide if it had been shared earnestly, ironically, or to disagree with it. "Share with note" gives users an opportunity to attach a (hopefully pithy) commentary to their share. Also in this launch is the "Note in Reader" bookmarklet (internally called "Tag Anything") that allows users to share arbitrary pages through Reader.
August 2008: Incorporating the lessons learned from Reader's initial friends feature, the preferred Google social model is revamped. Instead of a symmetric friend list based on Google Talk buddies, there is a separate, asymmetric list that can be managed directly within Reader. The asymmetry is "push"-style: users decide to share items with some of their contacts, but it's up those contacts to actually subscribe if they wish (think "Incoming" stream on Google+, where people are added to a "See my Reader shared items" circle). This feature is brought to life by Dolapo Falola, who injects some much-needed humor into the Reader code: the unit tests use the Menudo band members to model relationships and friends acquire a (hidden) "ex-girlfriend" bit.
March 2009: After repeated user requests, (and enabled by more powerful ACL supported added by Susan Shepard) comments on shared items are launched. Once again Dolapo is on point for the frontend side, while Derek Snyder does all the backend work and makes sure that Reader won't melt down when checking whether to display that "you have new comments" icon. The ability of the backend and user interface to handle multiple conversations about an item is stress-tested with a particularly popular Battlestar Galactica item.
May 2009: Bundles are launched, extended sharing from just individual tags to collections of feeds.

Also as part of this launch, intern Devin Kennedy's trigonometry skills are put to good use in creating an easter egg animation triggered when liking or un-liking an item after activating the Konami code.
August 2009: Up until this point, one-click sharing had mainly been for intra-Reader use only (though there were a few third-party uses, some hackier than others). With the launch of Send to (also Devin's work), Reader can now "feed" almost any other service.
February 2010: The launch of Google Buzz posed some interesting questions for the Reader team. Should items shared in Reader show up in Buzz? (yes!) Should we allow separate conversations on an item in Buzz versus Reader? (no!) With a lot of behind the scenes work, sharing and comments in Reader are re-worked to have close ties to Buzz, such that even non-Reader-using friends can finally get in on the commenting action.
March 2010: Partly as a tongue-in-cheek reaction to social developments within Google, and partly to help out some Buzz power users who were complaining that all the social features in Reader were slowing it down, I add a secret (though not for long) anti-social mode.
May 2010: Up until this point, it was possible to have publicly-shared items but only allow certain friends to comment on them. Though powerful, this amount of flexibility was leading to complexity and user confusion and workarounds. To simplify, we switch to offering just two choices for shared items, and in either case if you can see the shared item, you can comment on it.
As you can see, it's been a long trip, and with the switch to Google+ sharing features, Reader is on its fourth social model. This much experimentation in public led to some friction, but I think this incremental approach is still the best way to operate. Whether you're a sharebro, a Reader partier, a Gooder fan, the number 1 sharer or someone who "like"-d someone else, I am are very grateful that you were part of this experiment (and I'm guessing the rest of the past and present team is grateful too). And if you're looking to toast Reader for all its social stumbles accomplishments, the preferred team drink is scotch.
 I was pleasantly surprised that the full stack worked, including bits that relied on
I was pleasantly surprised that the full stack worked, including bits that relied on 
 Along these lines, I thought I would play around with the
Along these lines, I thought I would play around with the  Once I had that working, it seemed like a straightforward extrapolation to use the
Once I had that working, it seemed like a straightforward extrapolation to use the 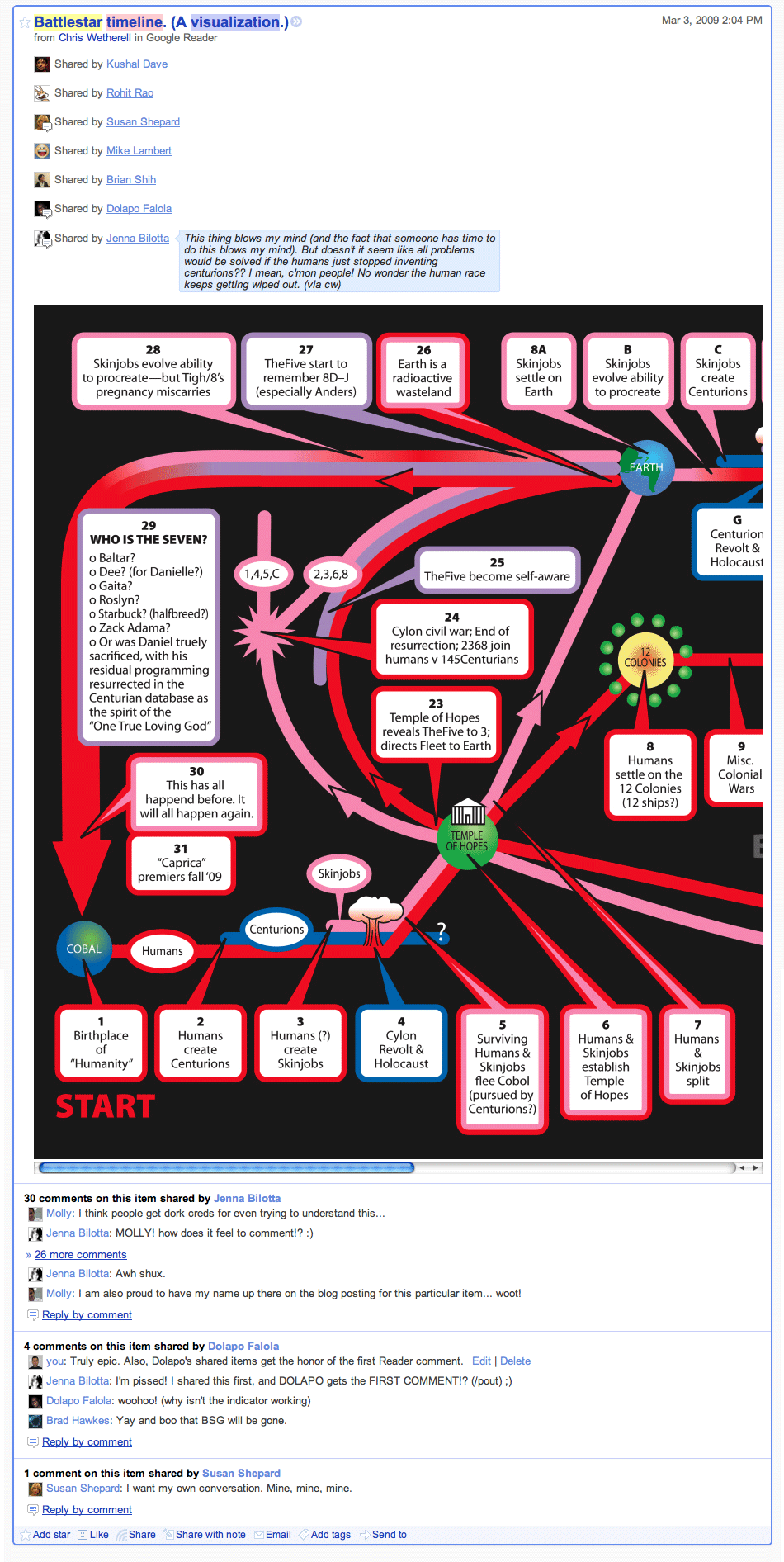{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}