RetroGit #

tl;dr: RetroGit is a simple tool that sends you a daily (or weekly) digest of your GitHub commits from years past. Use it as a nostalgia trip or to remind you of TODOs that you never quite got around to cleaning up. Think of it as Timehop for your codebase.
It's now been a bit more than two years since I've joined Quip. I recall a sense of liberation the first few months as we were working in a very small, very new codebase. Compared with the much older and larger projects at Google, experimentation was expected, technical debt was non-existent, and in any case it seemed quite likely that almost everything would be rewritten before any real users saw it¹. It was also possible to skim every commit and generally have a sense that you could keep the whole project in your head.
As time passed, more and more code was written, prototypes were replaced with “productionized” systems and whole new areas that I was less familiar with (e.g. Android) were added. After about a year, I started to have the experience, familiar to any developer working on a large codebase for a while, of running blame on a file and being surprised by seeing my own name next to foreign-looking lines of code.
Generally, it seemed like the codebase was still manageable when working in a single area. Problems with keeping it all in my head appeared when doing context switches: working on tables for a month, switching to annotations for a couple of months, and then trying to get back into tables. By that point tables had been “swapped out” and it all felt a bit alien. Extrapolating from that, it seemed like coming back to a module a year later would effectively mean starting from scratch.
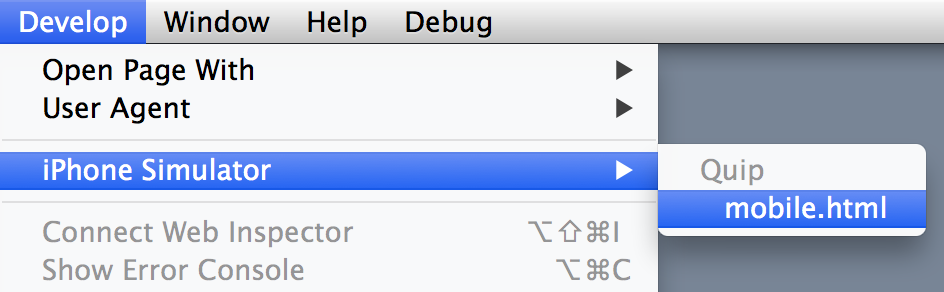
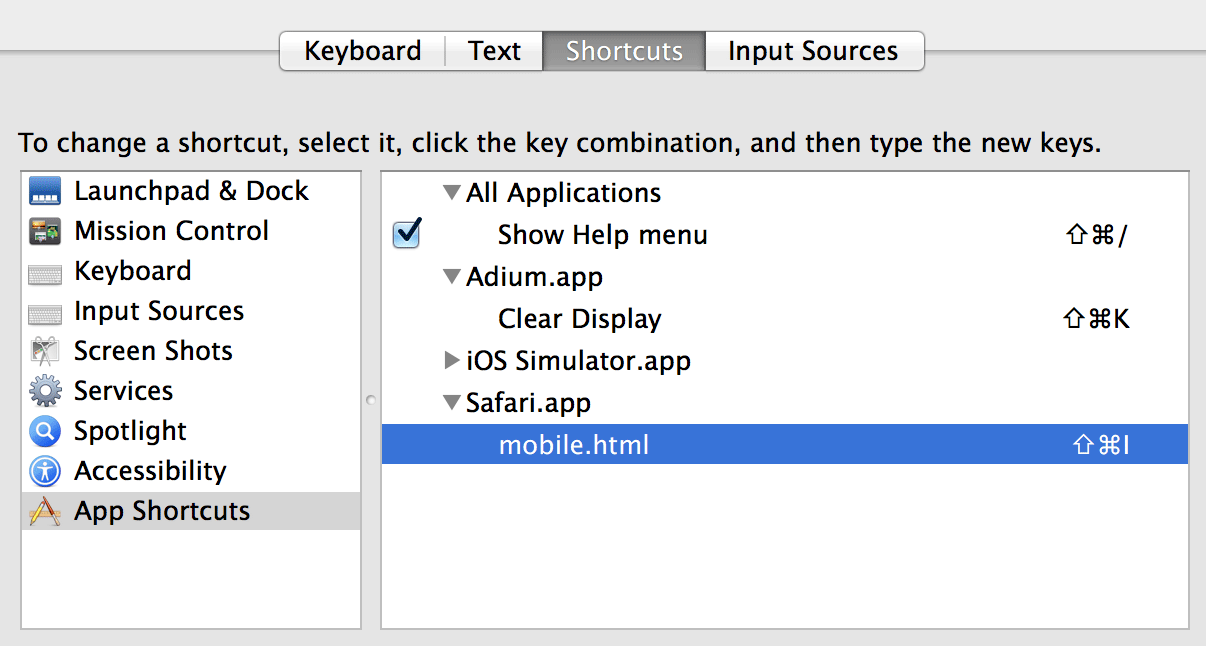
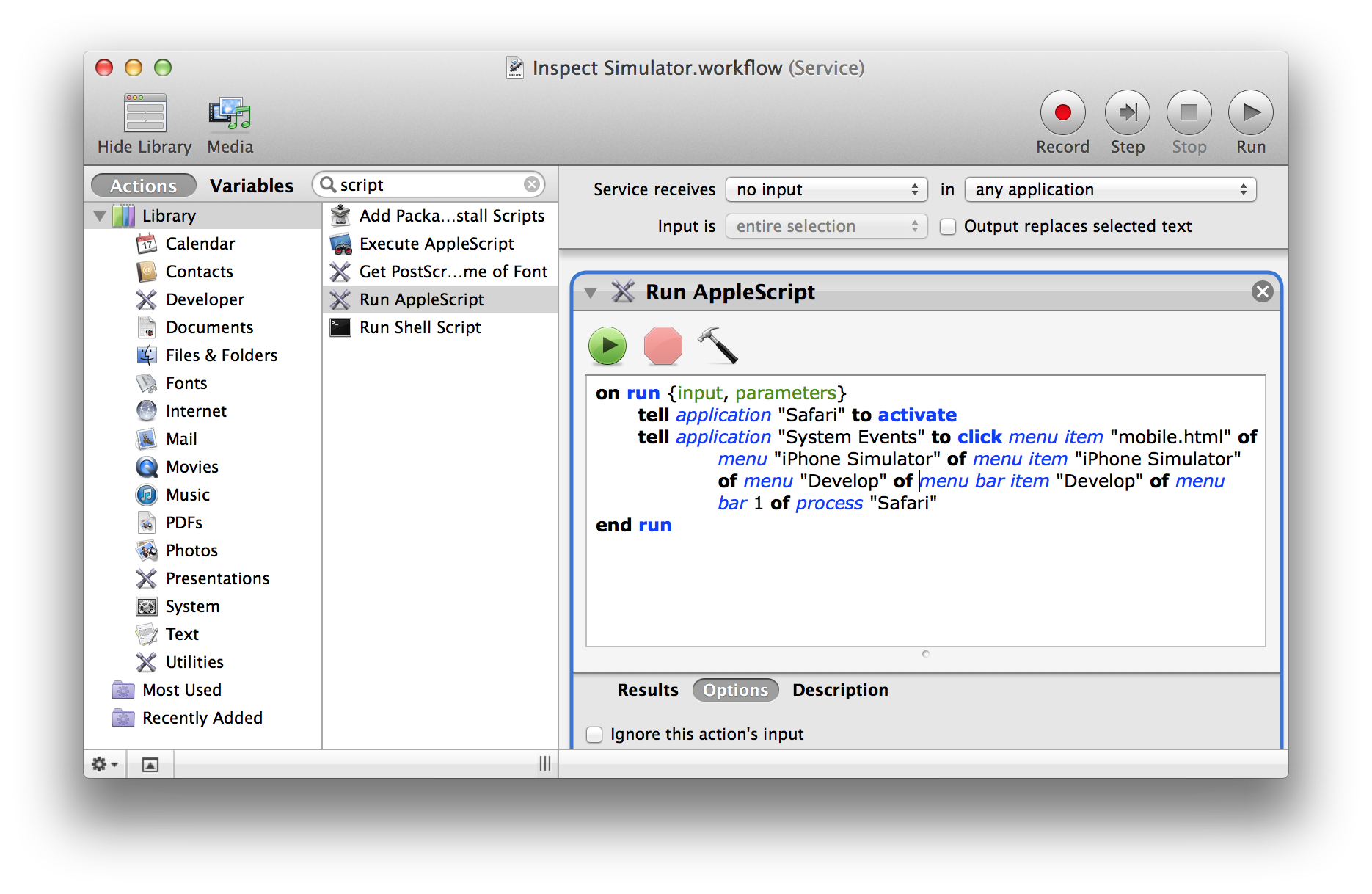
I wondered if I could build a tool to help me keep more of the codebase “paged in”. I've been a fan of Timehop for a while, back to the days when they were known as 4SquareAnd7YearsAgo. Besides the nostalgia factor, it did seem like periodic reminders of places I've gone to helped to keep those memories fresher. Since Quip uses GitHub for our codebase (and I had also migrated all my projects there a couple of years ago), it seemed like it would be possible to build a Timehop-like service for my past commits via their API.
I had also wanted to try building something with Go², and this seemed like a good fit. Between go-github and goauth2, the “boring” bits would be taken care of. App Engine's Go runtime also made it easy to deploy my code, and it didn't seem like this would be a very resource-intensive app (famous last words).
I started experimenting over Fourth of July weekend, and by working on it for a few hours a week I had it emailing me my daily digests by the end of the month. At this point I ran into what Akshay described as the “eh, it works well enough” trough, where it was harder to find the motivation to clean up the site so that others could use it too. But eventually it did reach a “1.0” state, including a name change, ending up with RetroGit.
The code ended up being quite straightforward, though I'm sure I have quite a ways to go before writing idiomatic Go. The site employs a design similar to Tweet Digest, where it doesn't store any data beyond an OAuth token, and instead just makes the necessary API calls on the fly to get the commits from years past. The GitHub API behaved as advertised — the only tricky bit was how to handle the my aforementioned migrated repositories. Their creation dates were 2011-2012, but they had commits going back much further. I didn't want to “probe” the interval going back indefinitely, just in case there were commits from that year — in theory someone could import some very old repositories into GitHub³. I ended up using the statistics endpoint to determine when the first commit for a user was in a repository, and persisting that as a “vintage” timestamp.
I'm not entirely happy with the visual design — I like the general “retro” theme, but I think executing it well is a bit beyond my Photoshop abilities. The punch card graphic is based on this “Fortran statement” card from this collection. WhatTheFont! identified the header font as ITC Blair Medium. Hopefully the styling within the emails is restrained enough that it won't affect readability. Relatedly, this was my first project where I had to generate HTML email, and I escaped with most of my sanity intact, though some things were still annoying. I found the CSS compatibility tables from MailChimp and Campaign Monitor, though I'm happy that I don't have care too much about more “mass market” clients (sorry Outlook users).
As to whether or not RetroGit is achieving its intended goal of helping me keep more of the Quip codebase in my head, it's hard to say for sure. One definite effect is that I pay more attention to commit messages, since I know I'll be seeing them a year from now. They're not quite link bait, but I do think that going beyond things like “Fixes #787” to also include a one-line summary in the message is helpful. In theory the issue has more details as to what was broken, but they can end up being re-opened, fixes re-attempted, etc. so it's nice to capture the context of a commit better. I've also been reminded of some old TODOs and done some commenting cleanups when it became apparent a year later that things could have been explained better.
If you'd like to try it yourself, all the site needs is for you to sign in with your GitHub account. There is an FAQ for the security conscious, and for the paranoid running your own instance on App Engine should be quite easy — the README covers the minimal setup necessary.
- It took me a while to stop having hangups about not choosing the most optimal/scalable solution for all problems. I didn't skew towards “over-engineered” solutions at Google, but somehow enough of the “will it scale” sentiment did seep in.
- My last attempt was pre-Go 1.0, and was too small to really “stick”.
- Now that Go itself has migrated to GitHub, the Gophers could use this to get reminders of where they started.

{kind=link}
{kind=link}