Like many others I’ve spent a lot of time over the past year playing the New York Times’ Spelling Bee puzzle. For those that are not familiar with it, it’s a word game where you’re tasked with finding as many words as possible that can be spelled with the given 7 letters, with the center letter being required. I have by no means mastered it — there are days when getting to the “Genius” ranking proves hard. Especially at those times, I’ve idly thought about how trivial it would be to make a cheating program that applies a simple regular expression through a word list (or even uses something already made). However, that seemed both crude and tedious (entering 7 whole letters by hand).
When thinking of what the ideal bespoke tool for solving Spelling Bee would be, apps like Photomath or various Sudoku solvers came to mind — I would want to point my phone at the Spelling Bee puzzle and get hints for what words to look for, with minimal work on my part. Building such an app seemed like a fun way to play around with the Vision and Core ML frameworks that have appeared in recent iOS releases. Over the course of the past few months I’ve built exactly that, and if you’d like to take it for a spin, it’s available in the App Store. Here’s a short demo video:
Object Detection
The first step was to be able to detect a Spelling Bee “board” using the camera. As it turns out, there are two versions of Spelling Bee, the print and digital editions. Though they are basically the same game, the print one has a simpler display. I ended up creating a Core ML model that had training data with both, with distinct labels (I relied on Jason to send me some pictures of the print version, not being a print subscriber myself). Knowing which version was detected was useful because the print version only accepts 5-letter words, while the digital one allows 4-letter ones.
To create the model, I used RectLabel to annotate images, and Create ML to generate the model. Apple has some sample code for object detection that has the scaffolding for setting up the AVCaptureSession and using the model to get VNRecognizedObjectObservations. The model ended up being surprisingly large (64MB), which was the bulk of the app binary size. I ended up quantizing it to fp16 to halve its size, but even more reduction may be possible.

|
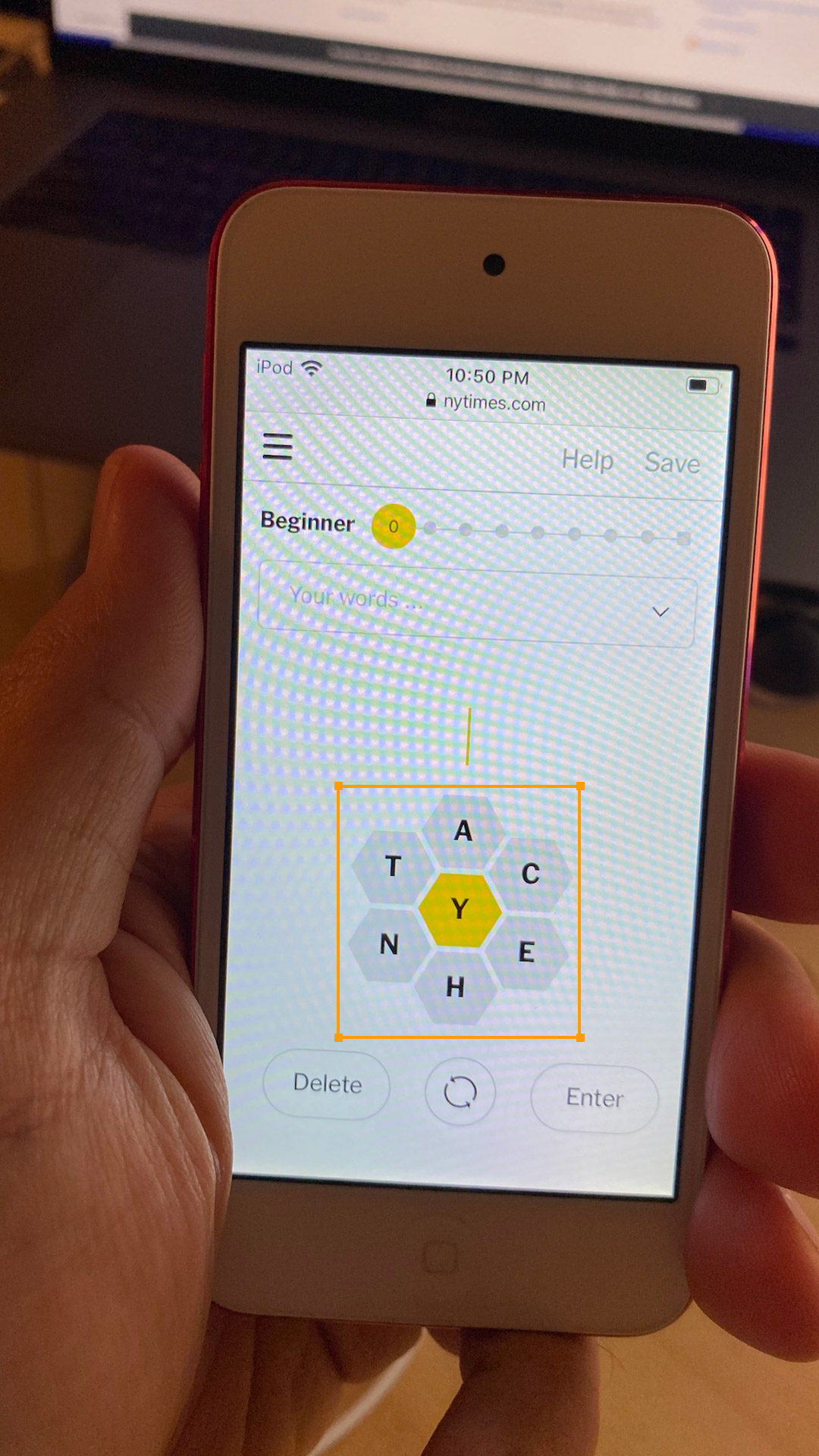
|
| Print edition |
Digital edition |
Text Extraction
Now that I knew where in the image the board was, the next task was to extract the letters in it. The vision framework has functionality for this too, and there’s also a sample project. However, when I ran a VNRecognizeTextRequest on the image, I was getting very few matches. My guess was that this was due to widely-spaced individual letters being the input, instead of whole words, which makes the job of the text detector much harder. It looked like others had come to the same conclusion.
I was resigned to having to do more manual letter extraction (perhaps by training a separate object detection/recognition model that could look for letters), when I happened to try Apple’s document scanning framework on my input. That uses the higher-level VNDocumentCameraViewController API, and it appeared to be able to find all of the letters. Looking at the image that it generated, it looked like it was doing some pre-processing (to increase contrast) before doing text extraction. I added a simple Core Image filter that turned the board image into a simple black-and-white version and then I was able to get much better text extraction results.
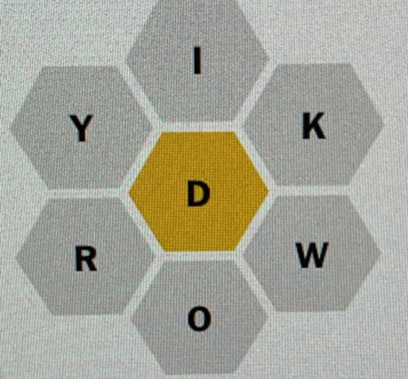
|
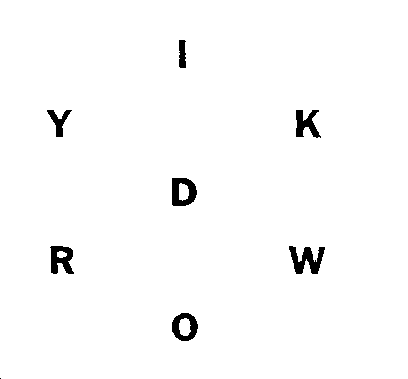
|
| Captured board image |
Processed and simplified board image |
The only letter that was still giving me trouble was “I”. Presumably that’s because a standalone capital "I" looks like a nondescript rectangle, and is not obviously a letter. For this I did end up creating a simple separate object recognition model that augments the text extraction result. I trained with images extracted from the processing pipeline, using the somewhat obscure option to expose the app’s Documents directory for syncing via iTunes/finder. This recognizer can be run in parallel with the VNRecognizeTextRequest, and the results from both are combined.
Board Letter Detection
I now had the letters (and their bounding boxes), but I still needed to know which one was the center (required) letter. Though probably overkill for this, I ended up converting the centers of each of the bounding boxes to polar coordinates, and finding those that were close to the expected location of each letter. This also gave me a rough progress/confidence metric — I would only consider a board’s letter fully extracted if I had the same letters in the same positions from a few separate frames.
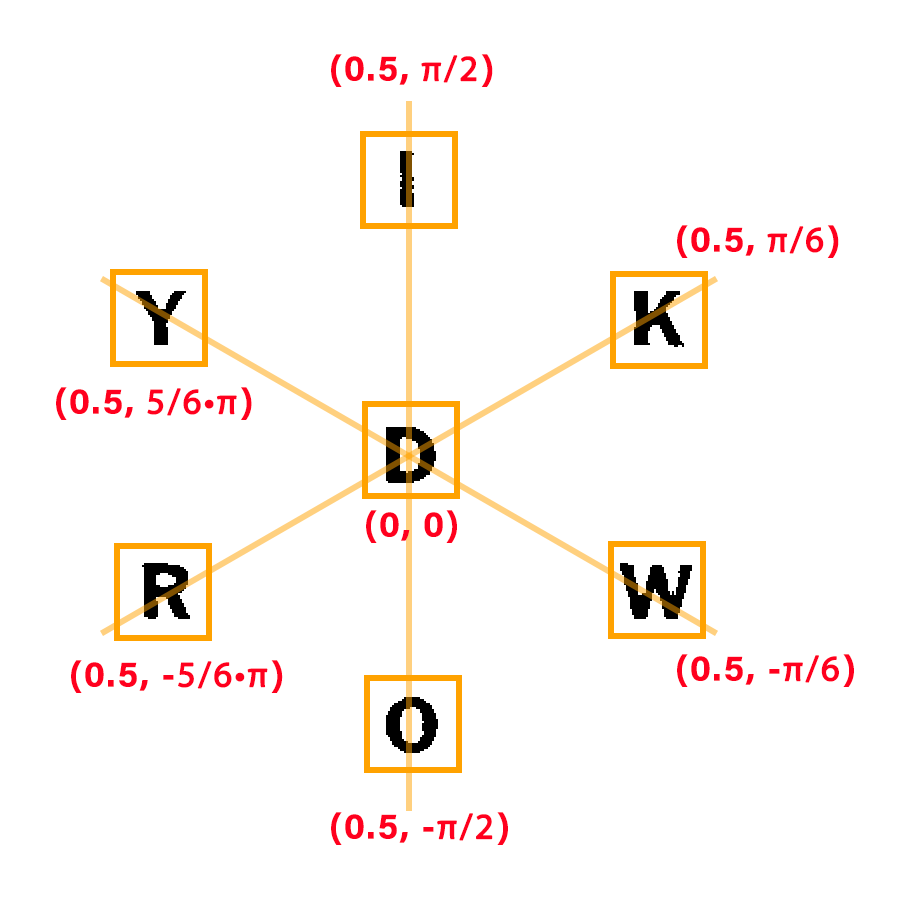
Dictionary Word Lookup
Once I knew what the puzzle input was, the next step was to generate the possible words that satisfied it. Jason had helpfully generated all possible solutions, but that was for the print version, which did not support 4-letter words. I ended up doing on-device solution generation via a linear scan of a word list — iOS devices are fast enough and the problem is constrained enough that pre-generation was not needed.
One of the challenges was determining what a valid word is. The New York Times describes Spelling Bee as using “common” words, but does not provide a dictionary. The /usr/share/dict/words list which is commonly used for this sort of thing is based on an out-of-copyright dictionary from 1934, which would not have more recent words. I ended up using the 1/3 million most frequent words from the Google Web Trillion Word Corpus, with some filtering. This had the advantage of sorting the words by their frequency of use, making the word list ascend in difficulty. This list does end up with some proper nouns, so there's no guarantee that all presented words are acceptable as solutions, but it was good enough.
Word Definition Display
To make the app more of a “helper”, I decided to not immediately display the word list, but to have a “clue” in the form of each word’s definitions. iOS has a little-known helper for displaying word definitions - UIReferenceLibraryViewController. While this does display the definition of most words, it doesn’t allow any customization of the display, and I wanted to hide the actual word.
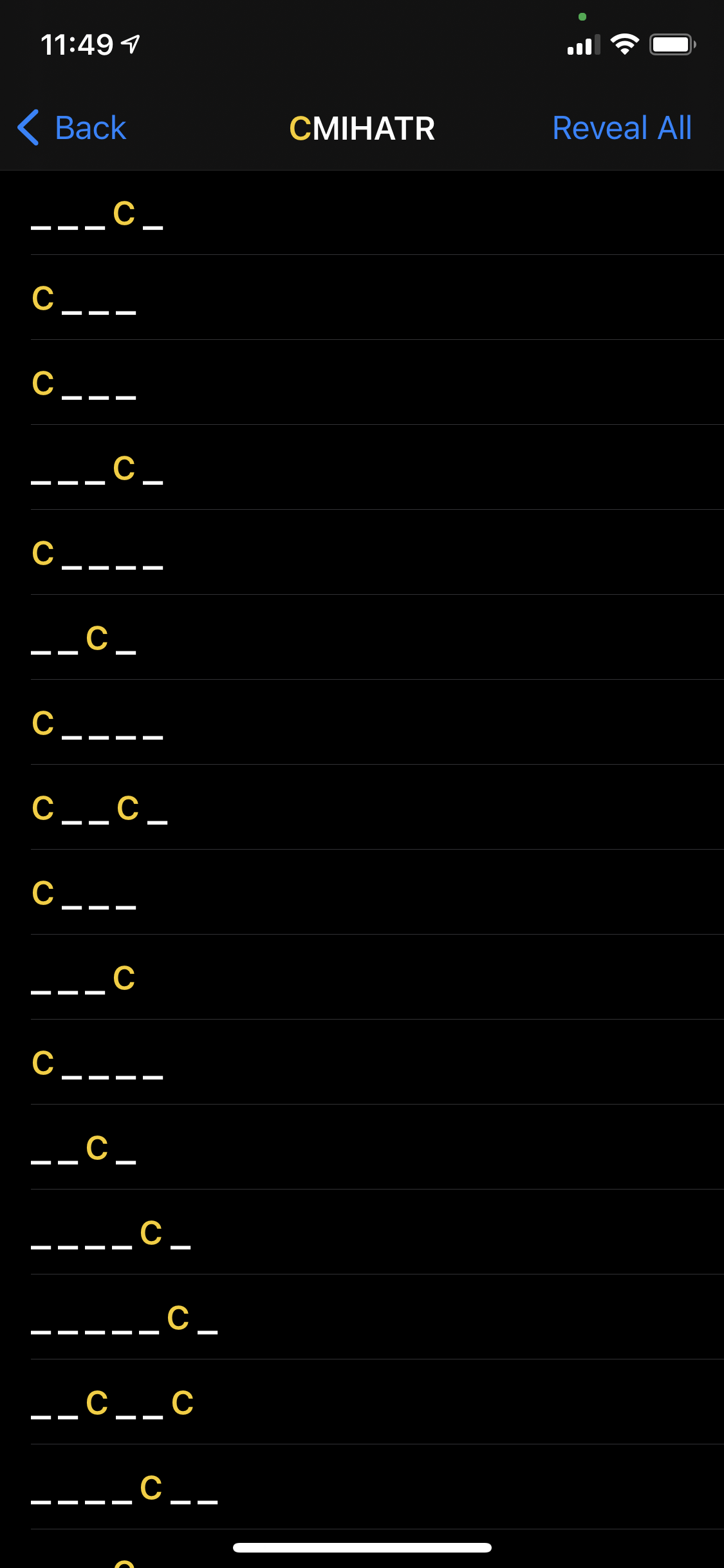
|
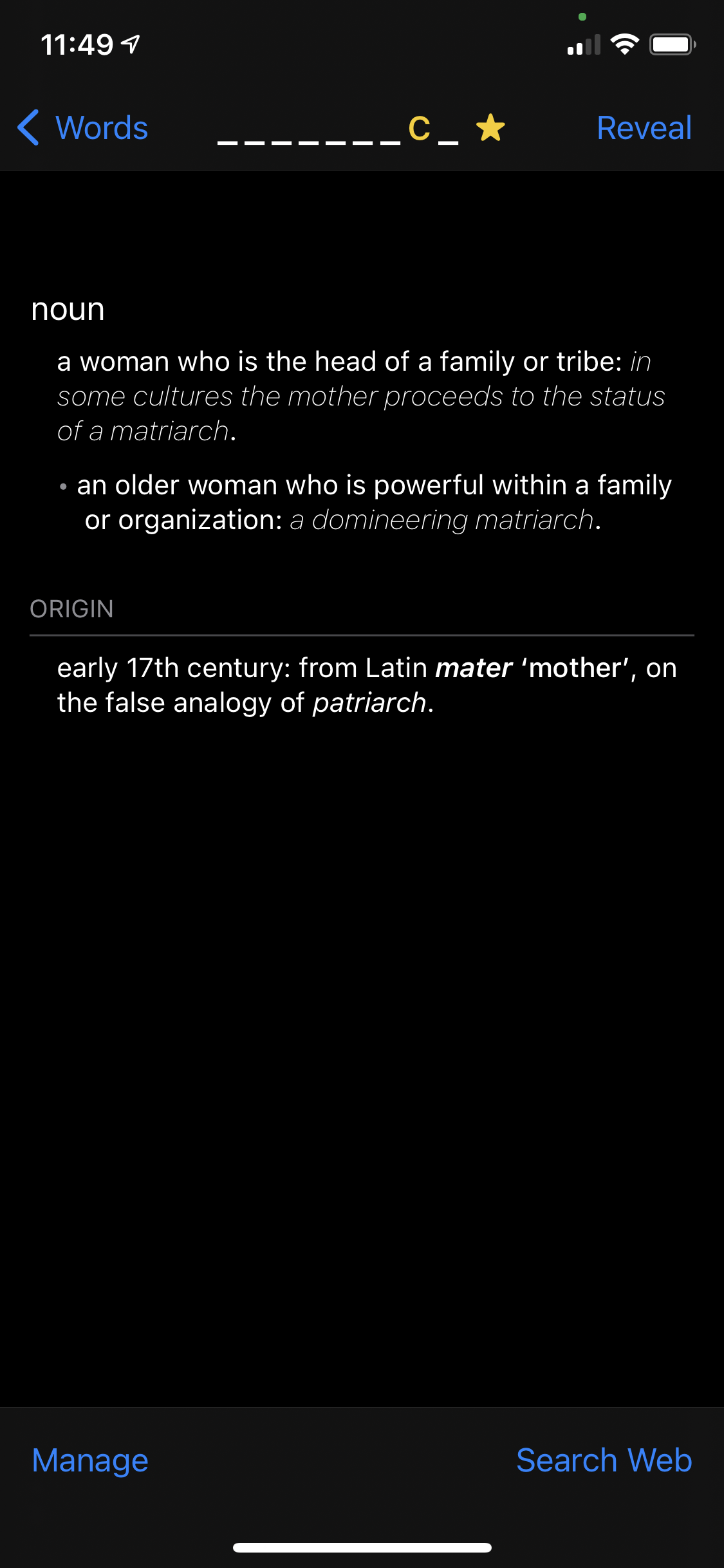
|
| Word list |
Definition (with word hidden) |
It turns out it’s implemented via a WKWebView, and thus it’s possible to inject a small snippet of JavaScript to hide and show definition. The whole point of this project had been to learn something different from the “hybrid app with web views” world that I inhabit at Quip, but sometimes you just can’t escape the web views.
Polish
Now that I had the core functionality working end-to-end, there were still a bunch of finishing touches needed to make it into an “app” as opposed to a tech demo. I ended up adding a slash screen, a “reticle” to make the scanning UI more obvious, and a progress display to show the letters that have been recognized so far.
This was a chance to experiment with SwiftUI. While it was definitely an improvement over auto-layout or Interface Builder, I was still disappointed by the quality of the tooling (Xcode previews would often stop refreshing, even for my very simple project) and the many missing pieces when it comes to integrating with other iOS technologies.
Getting it into the App Store
Despite being a long-time iOS user and developer, this was my first time submitting one of my own apps to the App Store. The technical side was pretty straightforward — I did not encounter any issues with code signing, provisioning profiles or other such things that have haunted Apple platform developers for the past decade. Within a day, I was able to get a TestFlight build out.
However, actually getting the app approved for the App Store was more of an ordeal. I initially got contradictory rejections from Apple (how can app both duplicate another and not have “enough” functionality) and all interactions were handled via canned responses that were not helpful. I ended up having to submit an appeal to the App Review Board to get constructive feedback, after which the app was approved without further issues. I understand the App Store is appealing target for scammers, but having to spend so much reviewer bandwidth on a free, very niche-y app does not seem like a great use of limited resources.
Peeking Inside
If you’d like to take a look to see how the app is implemented, the source is available on GitHub.